II.CUDA & GPU 基础
GPU的基本属性。
- 做问题一的时候总觉得少点什么,原来是缺了这一节课没有听,所以grid啥的知识点不明白。
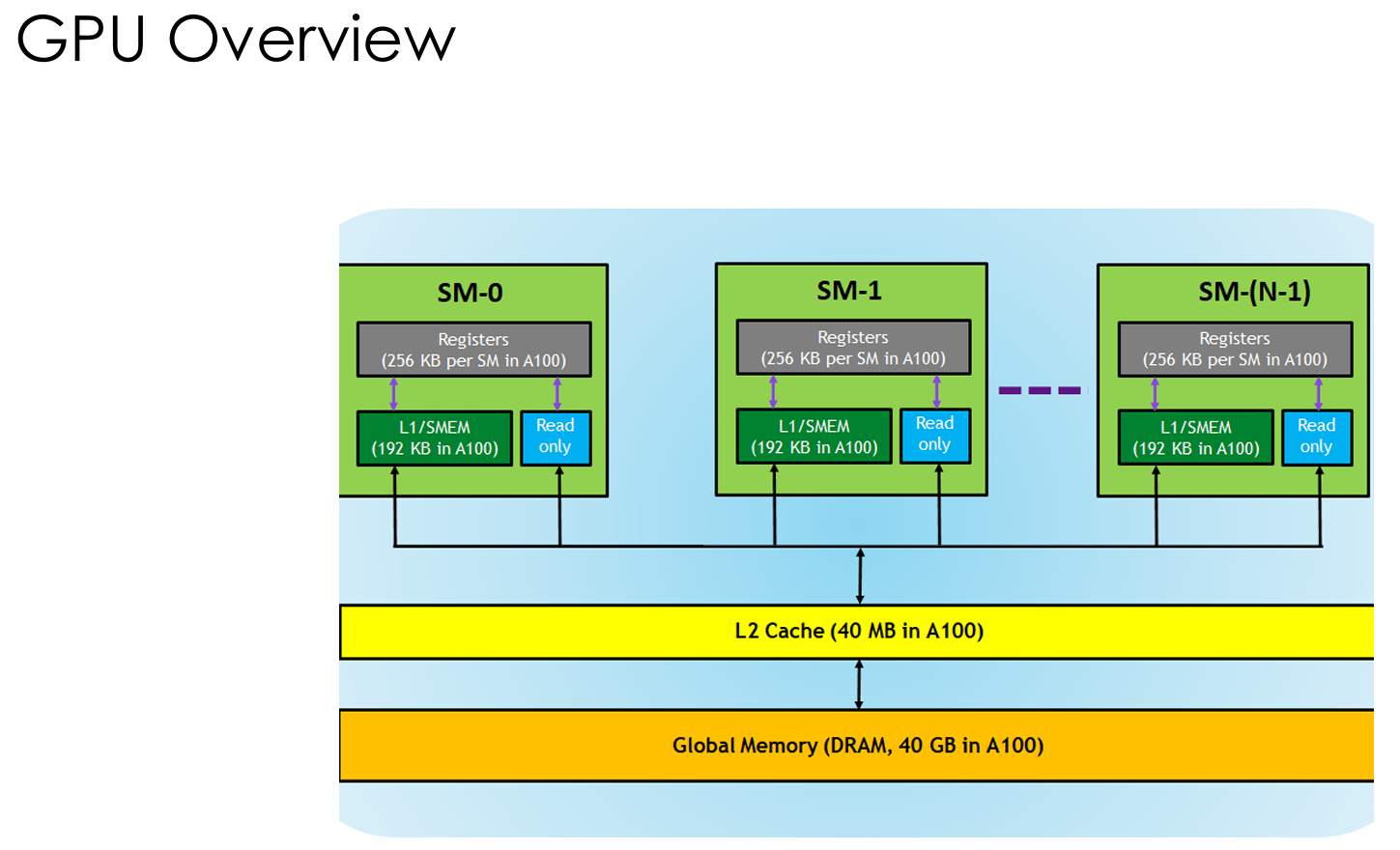
- SM/SMP(Streaming Multi-processor)
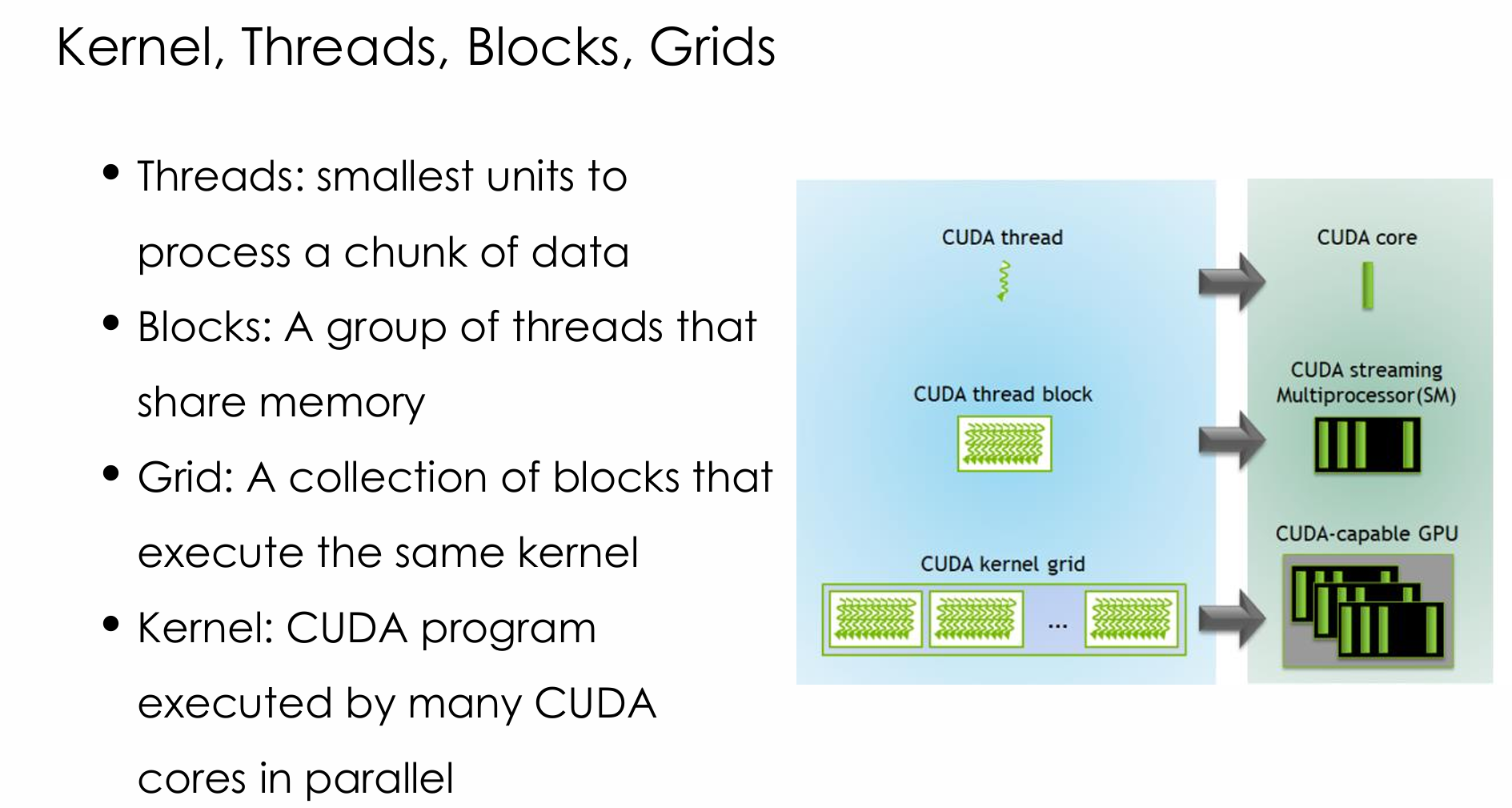
- 线程(thread)就是最小的工作单元,对应一个cuda/tensor core。core就是alu嵌入到gpu中
- 块(block)就是共享内存的线程块,每一个前文提到的SM就对应一个Block,然后会包含很多的线程,都并行工作
- 网(grid)就是一堆block的集合,然后对应的就是GPU
- Kernel就是GPU代码,我们不叫他们program,是一个fancy的名字
GPU是为了SIMD(simple instruction multiple processing)
More power GPU generally means:
- More SMs
- More core per SM
- More powerful cores
程序在GPU上的执行流程
- 编程:(GPU -CUDA)
- 编译:(GPU -nvcc)
- 执行:(GPU -driver调度到GPU上)
- GPU的计算模块怎么设计的
- GPU的内存模块怎么设计的
- 3.程序怎么调度到GPU上,怎么在SM(GPU内一级计算单元)间调度, 怎么在SM内执行?
CUDA
CUDA是c-like的,为开发者准备在GPU编程的,CUDA的设计完全贴合grid/block/thread 概念。
//all are CPU codes
const int Nx = 12; const int Ny = 6; //矩阵的形状
dim3 threadsPerBlock(4,3,1);
dim3 numBlocks(Nx/threadsPerBlock.x,
Ny/threadsPerBlock.y,1);
// assume A,B,C are allocated Nx x Ny float arrays
//this call will trigger execution of 72 CUDA threads:
// 6 thread blocks of12 threads each
matrixAdd<<<numBlocks, threadsPerBlock>>>(A,B,C); //the only GPU code上面的代码就是在启动一个kernel之前定义的metadata。基本上说,就是这个kernel会在多少个Block以及每个Block多少个thread上跑。这是静态定义的.
这里我们说一个GPU就只有一个grid,基本概念为:
- GridDim: The dimensions of the grid
- blockIdx: The block index within the grid
- blockDim: The dimensions of a block
- threadIdx: The thread index within a block 所以这里没有GridId或threadDim。有的话也都为1
CUDA program
除了上面说的CPU代码,还需要kernel的具体实现。
__device__ float doubleValue(float x)
{
return 2 * x;
}
// kernel definition
__global__ void matrixAddDoubleB(
float A[Ny][Nx],
float B[Ny][Nx],
float C[Ny][Nx]
)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
C[j][i] = A[j][i] + doubleValue(B[j][i]);
}这段kernel实现的是C = A + 2B这一个算子。
__global__标记代表这是一个cuda kernel- 每一个thread只做总工作的一部分
- 所以这里的
i,j其实就相当于去计算了这个thread在排布中的位置 - 注意避免写入冲突,线程不能重复写入同一个区域。 这里可以把前文有一张描述blockIdx等概念的图记在脑子里

计算出的(i,k)就是图中这个坐标。原来这个数据就是12*6的然后我们block是3*2,thread是4*3,这个thread的分布也是12*6的,所以能够对上,每一个线程只算一个数据。
我们把CPU code与GPU code严格分开,一个是串行,一个是SIMD并行,我们叫他们Host code和Device code。 cpu代码的作用就是定义kernel的元数据,其中的这个调用
matrixAdd<<<numBlocks, threadsPerBlock>>>(A,B,C); //the only GPU code值的返回会阻塞,并等待所有线程返回。但是cpu其实不会阻塞执行,如果下面还有代码会继续执行。所以下面的cpu执行和gpu是并行执行的 我们的解决方法是cuda synchronize这个函数
同步原语
__syncthreads(): wait for all threads in a block to arrive at this point cudasycnhronize(): sync between host and device
CUDA Control flow
gpu每个线程本来是做相同的事情,以相同的速度,但是如果有越界,或者其他条件判断的问题,控制流这个问题就会扰乱这个速度。 CUDA是static的,意思是他们不能在同一时间做不同的事情。
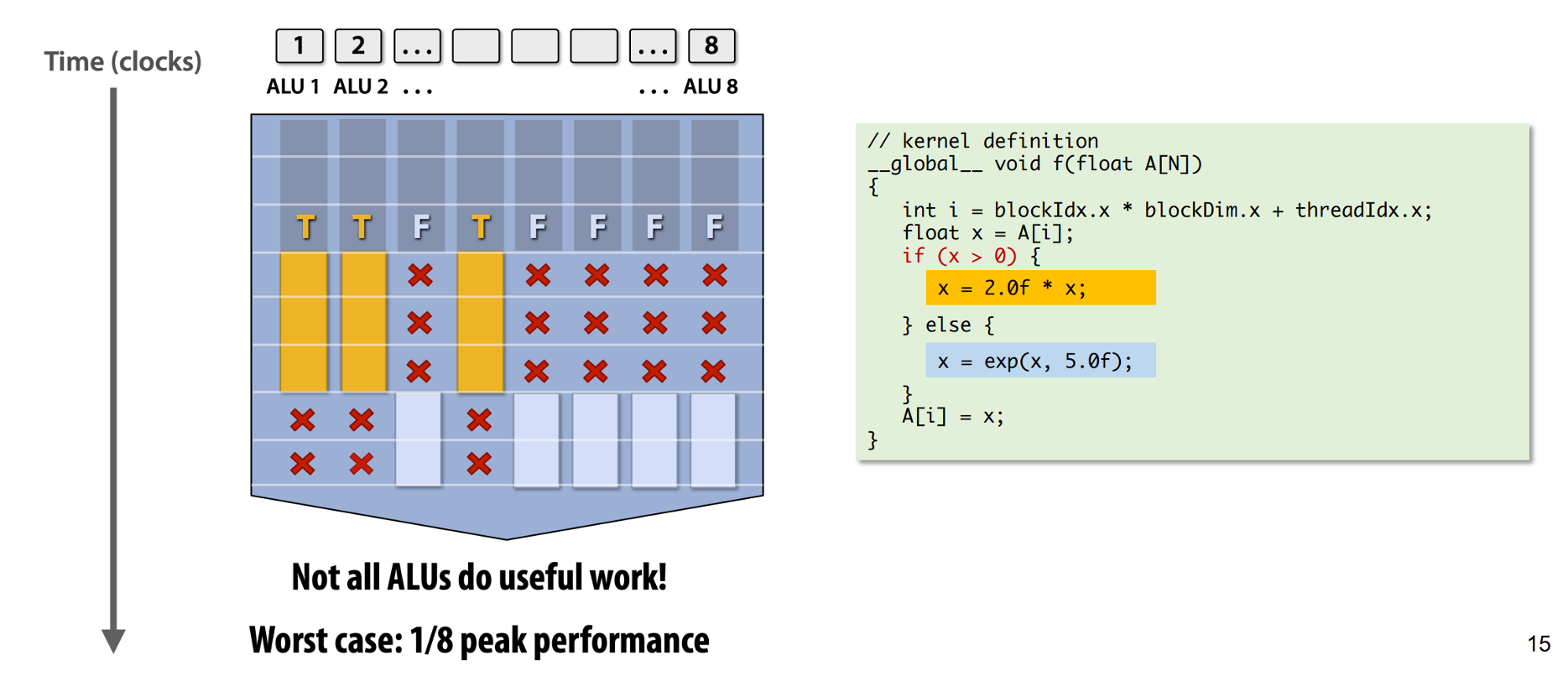
类似图中这种情况,T和F的线程不能同时做不同的事情,所以只能等待,每一个branch做不同的事情。非常低效,如果有更多的branch会更加低效。画叉的区域也称为bubble,这也是控制冒险,类似cpu的控制冒险产生bubble
- maskking
内存
- 我们以后将会用
- DRAM表示CPU mem
- HBM表示GPU mem。比cpu的更高速。
- 内存管理是
- CPU是页式分布
- GPU是直接写成内存池
- 二者无法互相直接访问 cuda也有相应的内存malloc代码
float* A = new float[N];
// populate host address space pointer A
for (int i = 0; i < N; i++)
A[i] = (float)i;
int bytes = sizeof(float) * N;
float* deviceA; // allocate buffer in
cudaMalloc(&deviceA, bytes); // device address space
// populate deviceA
cudaMemcpy(deviceA, A, bytes, cudaMemcpyHostToDevice);
// note: deviceA[i] is an invalid operation here (cannot
// manipulate contents of deviceA directly from host.
// Only from device code.)更多概念:Pinned Memory(页锁定内存)
- 属于主机(CPU)内存的一部分
- 针对 CPU 与 GPU 之间的数据传输做了优化
- 不会被操作系统分页(不可换页),也叫“锁页内存”
- 某些 CUDA API 只能用于 Pinned Memory
Kernel Execute
- 每个线程块由一个 SM 执行,并且在线程块执行期间不会迁移到其他 SM。
- 根据线程块的内存需求以及 SM 的内存资源,一个 SM 上可以同时驻留多个线程块。
Pasted image 20260519175539.png- 其中,warp 是 kernel 执行过程中的基本调度单位。
- 一个线程块由若干个 32 线程的 warp 组成。
- 每个时钟周期,warp 调度器会选择一个已经准备好的 warp,并将该 warp 分派到 CUDA 核心上执行。
Pasted image 20260519175614.png可以通过多warp调度来cover掉准备数据的时间,减少SM上的bubble
Warp 的形成规则
当一个 Thread Block 被分配到 SM 上时,硬件会自动将其中的线程按 threadIdx 顺序分组为 Warp:
Block 中的线程 ID 所属 Warp
0 ~ 31 Warp 0
32 ~ 63 Warp 1
64 ~ 95 Warp 2
... ...关键点:Warp 的划分是硬件行为,程序员无法干预。一个包含 256 个线程的 Block 会被拆为 8 个 Warp。如果 Block 大小不是 32 的整数倍(如 48 个线程),最后一个 Warp 中多余的线程位置会被“填充”但不执行有效工作,这会浪费硬件资源。
参考:AIinfraGuide
CUDA调度
因为不同的GPU有不同的SMP,但是用户写的kernel是静态的,可能数量更大,我们GPU无法分配 需要一个scheduler来满足不同的需求
- 核心假设:不同的thread可以乱序执行。(因为理想化都是并行的,所以乱序没关系) 比如:
深入理解 CUDA 调度(CUDA Scheduling)
- 在
1024 × 1024数据上执行 Conv1d - 每个线程块(thread block)包含 128 个 CUDA 线程
- 总共有 1024 个线程块
- 每个线程块需要申请
130 × 4 = 520字节共享内存(shared memory) - 已知:GPU 有 2 个 SM(流式多处理器),规格如下
- CUDA 的线程调度会是什么样子?
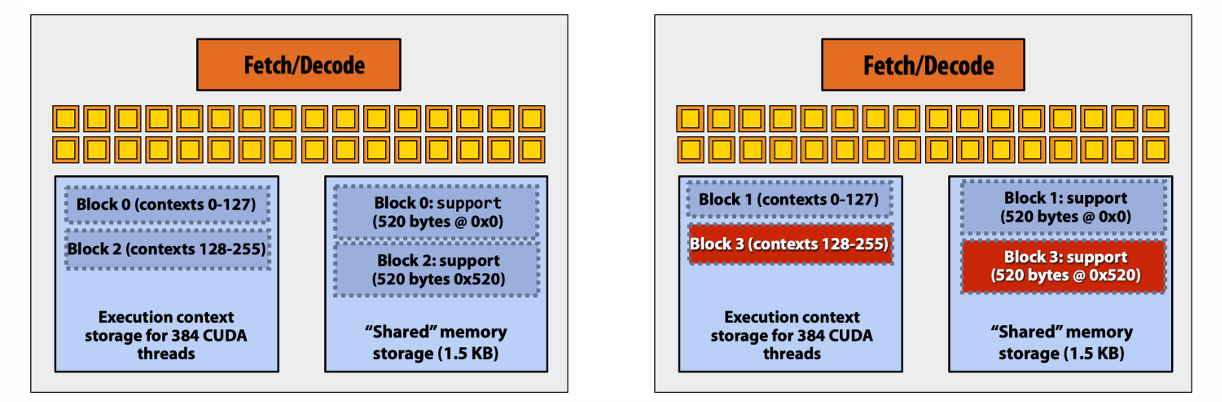
动态调度算法会按序在不同的SM的共享内存允许的情况下,把不同的块map在几个SM上,直到内存满了(over-subscription)。同一个SM上的block是并发执行的,他们代码不能有互相依赖的,block 之间应该是机器无关的:系统可以按任意顺序调度。 也就是说,block 到 SM 的映射不是按 block ID 固定映射,也不是所有 block 一次性同时运行,而是由 GPU 的 block scheduler 根据 SM 上剩余资源动态调度。资源够,就继续塞新的 block;资源不够,就等已有 block 执行完释放资源后再调度新的 block。
并行和并发
- 并发(Concurrency):指在同一时间段内处理多个任务,但在微观上同一时刻只有一个任务在执行。通过操作系统的时间片轮转或事件驱动机制,任务快速切换,使用户感知为同时进行。例如,单核 CPU 上多个线程轮流执行,每个线程在短时间片内运行,其他线程处于挂起状态 .
- 并行(Parallelism):指多个任务在同一时刻真正同时执行,需要多核 CPU 或分布式系统支持。每个任务在独立的处理器上运行,互不干扰。例如,多核 CPU 上每个核心同时执行不同线程,或者多个人同时用铁锹挖坑,每人独立完成任务.